Enhancing Sparse-View CT Reconstruction with Neural Networks
Florian Schiffers*, Haoyu Wei*, Tobias Würfl, and D. Shen, D. Kim, AK Katsaggelos, Oliver Cossairt
Figure 1: We propose a new architecture for holographic displays specifically designed for speckle reduction. Instead of a single coherent source of illumination, our design uses a grid of multiple sources, which sum incoherently at the image plane. By using two spatial light modulators (SLMs) with an air gap in between, we break correlations between the multiple sources enabling high-resolution holograms with significantly suppressed speckle. We experimentally demonstrate speckle reduction on both 2D images (left) and focal stacks with natural defocus blur (right).Paper Display
2-Step Sparse-View CT Reconstruction with a Domain-Specific Perceptual Network
Florian Schiffers*, Haoyu Wei*, Tobias Würfl, and D. Shen, D. Kim, AK Katsaggelos, Oliver Cossairt
We tackle the challenges in sparse-view Computed Tomography (CT) reconstruction, introducing a groundbreaking framework that enhances the quality of reconstructions from undersampled data. This work focuses on a novel two-step reconstruction approach and a domain-specific perceptual network to address the limitations of existing methods in sparse-view tomography.
Method
Innovative Two-Step Approach
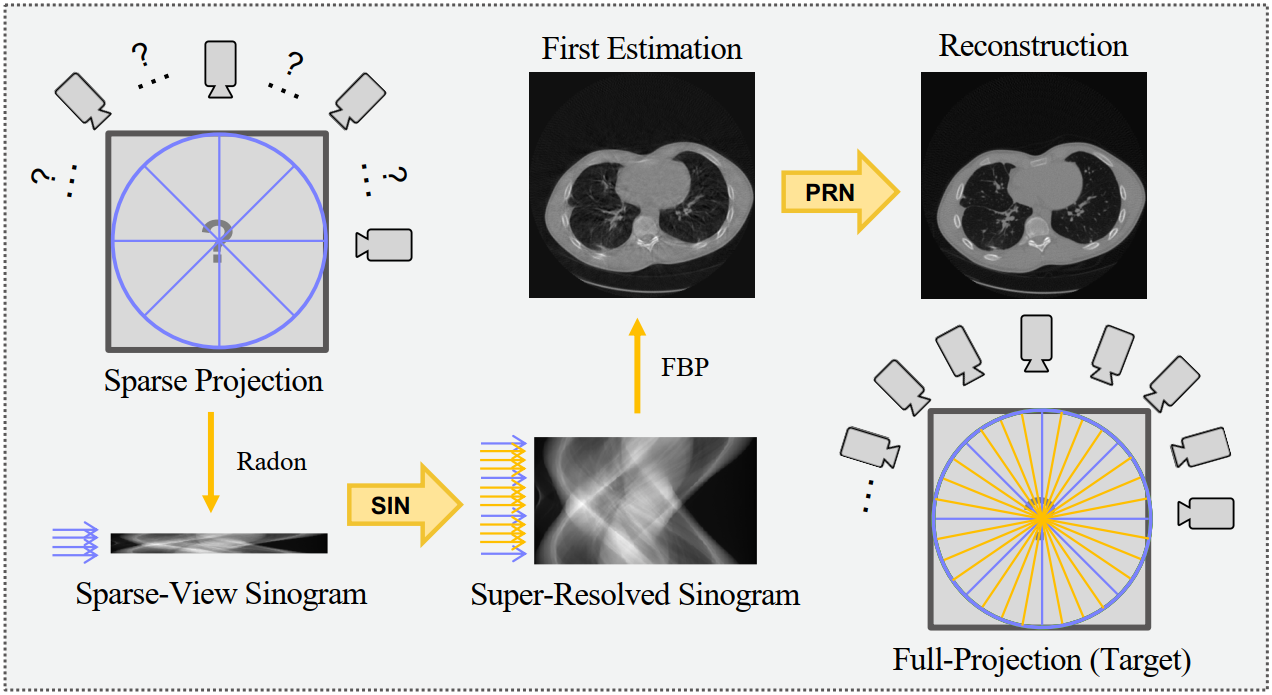
Our method employs a Sinogram Inpainting Network (SIN) in the first step, generating super-resolved sinograms and allowing for object reconstruction without severe streak artifacts. The second step utilizes a Postprocessing Refining Network (PRN) to refine the reconstruction by removing any remaining localized artifacts, ensuring high-quality results.
Discriminator Perceptual Network
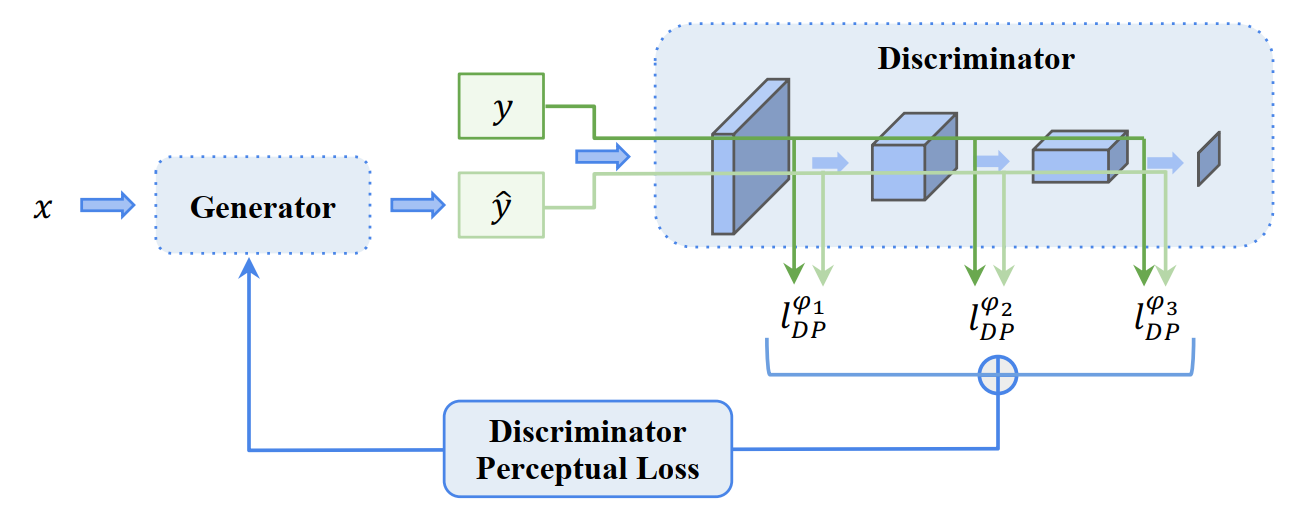
We introduce a Discriminator Perceptual (DP) loss, interpreting the initial layers of a discriminator as a feature extractor. This novel approach is trained simultaneously with the generator, promoting feature-level similarity and enhancing stability in our GAN training procedure.
Results and Discussion
Our approach demonstrates substantial improvement, achieving over 4 dB PSNR in reconstruction accuracy and effectively handling high compression ratios. The innovative domain-specific perceptual loss outperforms traditional methods in accuracy, efficiency, and memory usage.
Conclusion
This work presents a pioneering approach for enhancing sparse-view CT reconstruction, combining a two-step method and a domain-specific perceptual network. The introduced Discriminator Perceptual loss offers a stable and efficient solution, significantly advancing the field of sparse-view CT reconstruction.
For more details and to access the code, see the paper and visit GitHub.
Figure 2:
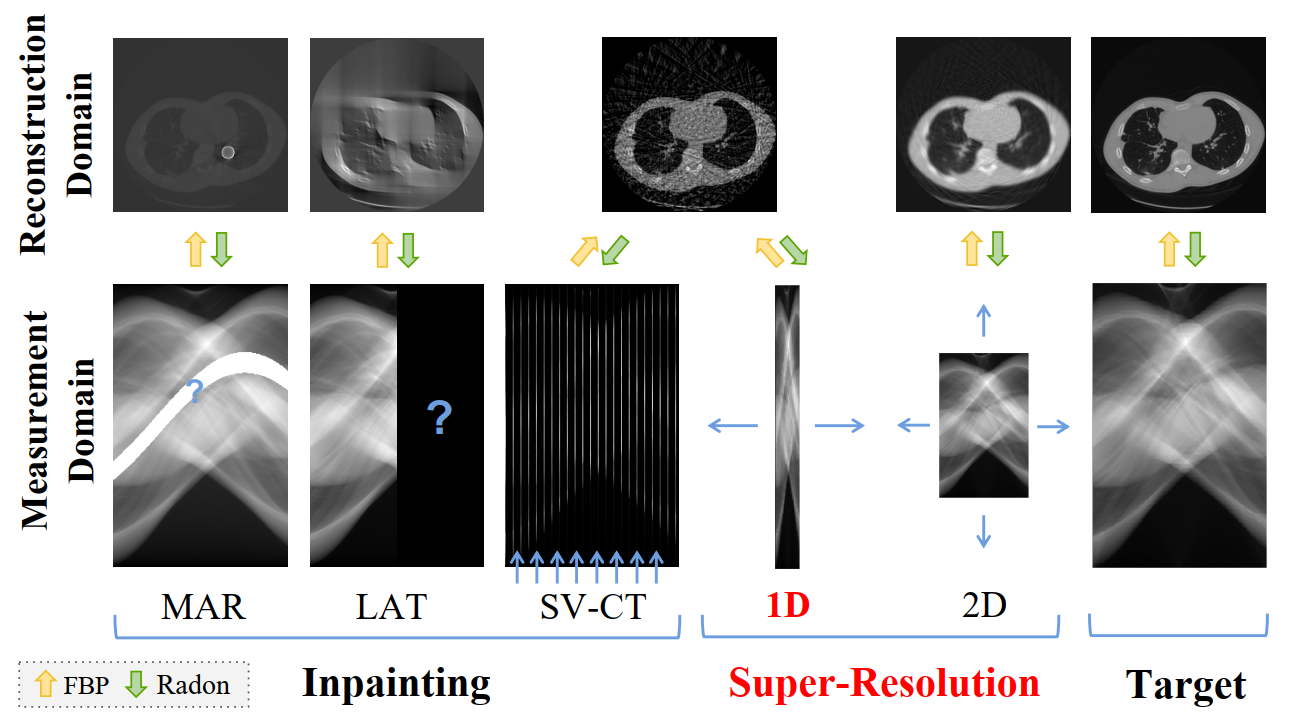
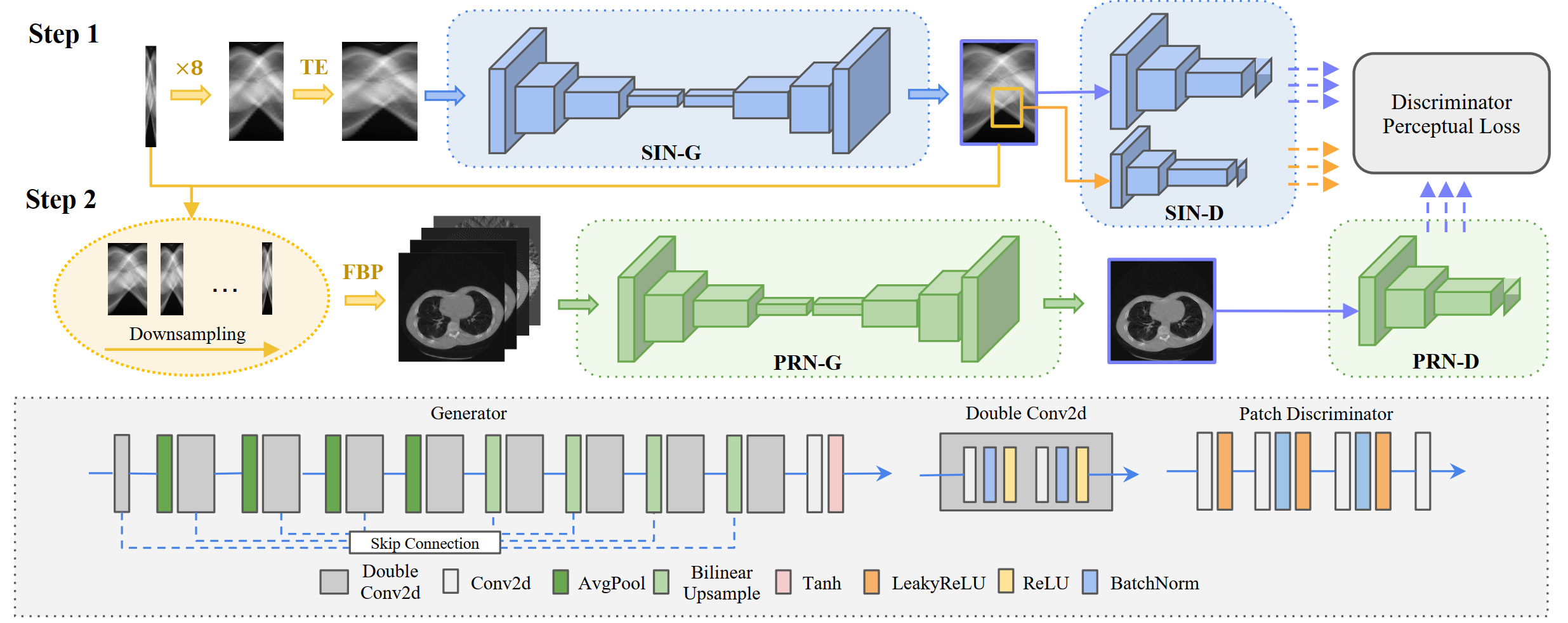
Different problems arising in tomographic imaging and their relations to our 1D-super-resolution task, such as metal artifact removal (MAR) and limited angle tomography (LAT). SparseView-CT is at the intersection of inpainting and super-resolution when viewed in measurement domain.Figure 3:Network Architecture of our proposed SIN-4c-PRN model. Top In step one, we linearly upsample a sparse-view sinogram and preprocess with our Two-Ends (TE) flipping method as input to the SIN model. In step two, the super-resolved sinogram is 1D-downsampled by different factors. FBP-reconstructions from the set of sinograms are concatenated as a cascaded input to the PRN. The patch discriminators SIN-D and PRN-D calculate pixel-wise adversarial losses of global or local generated images.
Additionally, each discriminator calculates a discriminator perceptual loss that enhances the generator's perceptual knowledge. Bottom Detailed architecture of our SIN and PRN modelsFigure 4:
Discriminator Perceptual Loss. The image pair generated from the input, and the target image are compared at each activation layer output in the discriminator. Pixel-wise losses are calculated for updating the generator.Figure 5:
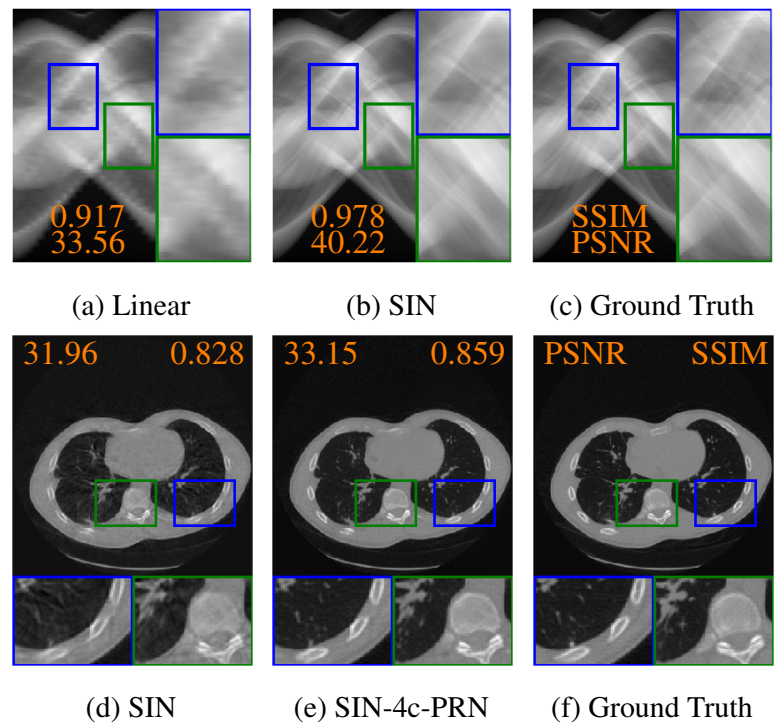
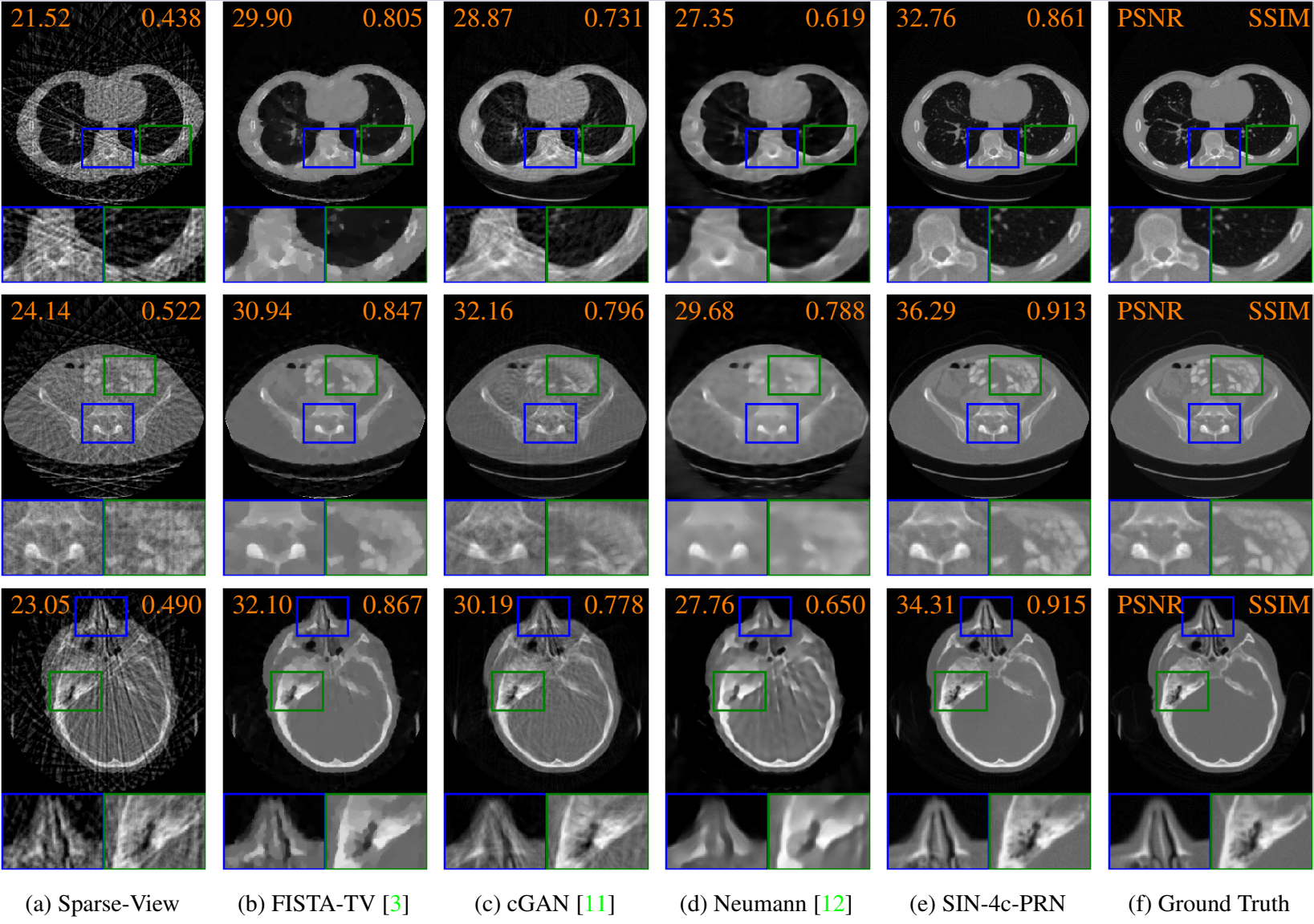
Our results in both measurement and reconstruction domains with zoom-in details compared with linear interpolation.Figure 6:Baseline results with zoom-in details. From top to bottom row: Chest: In our SIN-4c-PRN result, both soft tissues in the black region of the body and sharp edges of bones are maximally recovered compared to other methods. Abdomen:: Soft tissue with low contrast, such as in the green box are hard to recover from sinograms and pose a significant challenge for our networks.
%
Head: The high-frequency details in the nose and bone regions are reconstructed while others either fail or over-smooth them.